

 作者:星元
2023-11-18 16:26:41
作者:星元
2023-11-18 16:26:41 PYoCo是另一种基于NVIDIA eDiffi模型的文本到视频扩散模型。PYoCo可以通过描述主角、动作和位置等来生成合成视频。该模型采用一种新颖的视频噪声先验技术,其通过文本生成的视频有更好的同步性和真实性,还能够生成各种不同风格如写实风或中国水墨风。
这个颠覆性的新模型,是几位研究人员在NVIDIA当实习生期间研究出来的。谁看了不得说一句“高手在民间”~

以下内容翻译整理自:https://research.nvidia.com/labs/dir/pyoco/,转载请注明出处。
来自NVIDIA、芝加哥大学和马里兰大学的一组研究人员推出了PYoCo,这是一种建立在eDiff-I基础上的大规模文本到视频扩散模型,而eDiff-I是一种尖端图像生成模型,另外一种新颖的视频噪声先验。
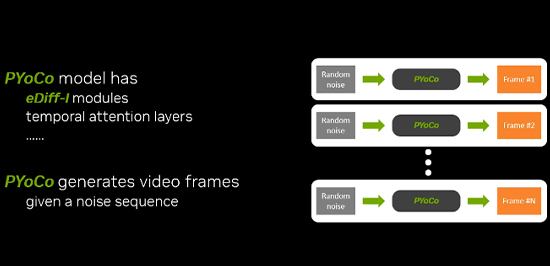
PYoCo可以通过描述主角、动作和位置等来生成合成视频。该模型还能够生成各种风格的视频(如写实或水墨风)。




据开发人员介绍,该模型结合了先前研究中的各种有效技术,例如时间注意力、联合图像-视频微调、级联生成架构和专家降噪器集成,在众多基准数据集上超越了其他方法。该团队分享的论文还强调了该模型实现高质量零镜头视频合成的能力,具有出色的照片真实感和时间一致性。


“我们提出了一种视频扩散噪声先验,用于微调文本到图像的扩散模型,用于文本到视频的合成,”该团队评论道。“我们表明,用这个先验微调文本到图像的扩散模型可以带来更好的知识转移和有效的训练。在小规模无条件生成基准上,我们实现了最新技术水平×更小的模型×更少的训练时间。且在零样本MSR-VTT评估中,我们的模型达到了9.73,这是目前最新、最先进的FID。”
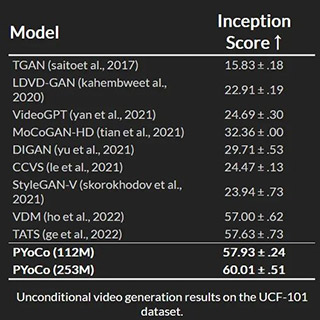
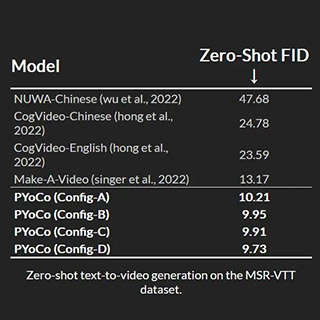
视频生成模型利用人工智能技术来创建或编辑视频。它们可以生成、增强、转换、压缩视频。根据原理和特点,视频生成模型可以分为四类:基于GAN、基于VAE、基于AR、基于Diffusion。其中,基于Diffusion的模型PYoCo是,用先进的图像生成模型eDiff-I中的知识来提高训练效率,同时结合时间注意力、联合图像视频微调、级联生成架构和去噪专家集成等技术,在无条件和零样本视频生成方面具有显著优势。

作为一种基于文本的视频生成模型,PYoCo可广泛应用于内容创作、教育培训、娱乐媒体和医疗诊断等领域。这一模型可以根据用户的需求和兴趣生成各种风格和主题的视频,为各行各业提供便捷、灵活、有效、有趣的解决方案。

版权声明 | 文章整理自网络,仅供学习参考,版权归属原作所有
如有问题,请及时与我们联系,我们将第一时间做出处理













 Android版下载
Android版下载
